Hashing(Part 3): a little application
The accompanying video is not yet available, coming soon.
Welcome back! Up until now, I've been very theoretical about hashing. I've talked about general principles and ideas, but not much in the way of application, so let's see a little example of where the rubber hits the road. Let's imagine that we need to manage admission to a concert, and we want to use software to do it. The main thing we need to keep track of is who has been admitted so that tickets can't be duplicated to allow multiple people in on a single ticket.
By the way, if you haven't read the previous articles in this series, I do refer to them and build on them, so I suggest you peruse them first.
First article: Hashing 101: What is hashing
Second article: Hashing(Part 2): making a basic hash function
Defining the problem
Let's say we have capacity for 100,000 attendees, and the concert is sold out. That means we need to keep track of 100,000 unique ticket numbers when people arrive at the concert. One of the simplest ways to do this is to keep a list of ticket numbers and then just check the list every time a new attendee arrives to see whether their ticket number is already in the list. This is relatively quick and easy for a small number of attendees, but the process gets slower with every new arrival, because we have to check their number against every other number in the list. Those algorithm geeks among you would know that this checking is an O(n) operation, that is the time taken to perform the check increases proportionally to the number of items in the list.
To give some real numbers to this, lets say it takes 10 microseconds to check whether two ticket numbers are the same. That means that the checking process for the first attendee takes 10 microseconds, the second 20, the third, 30 microseconds, and so on. This means that for the last few attendees, it will take nearly ten seconds second just to check that they have a valid ticket, and the total time spent checking will be nearly 14 hours. Not really practical is it?
A faster solution
So let's think about speeding this up. One option might be to perform the checking in parallel, but that's not a great solution for a few reasons I'm not going to get into right now, or we could use the ticket number as an index to our list of ticket numbers. This would be really fast, constant time or O(1), but it only works efficiently if the ticket numbers are all relatively close to each other. If the tickets happen to to be randomly spread over a large range of say, a billion numbers, in order to use this method, we would have to have a list that is 1 billion items long, and that could take a lot of space.
We can do better
We can come to a better solution to this problem if we think a bit more about what we are trying to do. In effect, what we want to do with every new attendee is to check the set ticket numbers from attendees who have already arrived to see if the ticket number is in there. The key word here is SET. What we need is some kind of way to efficiently represent a set without the process of checking the set getting too long as the set gets larger. In order to design this, let's go back to that method we were just considering of just using the ticket number as an index into the list. It's fast, really fast, one of the fastest things you can do on a computer, but if the size of the list required is too big, then we can't do it. Fast but can't be done? Not very useful. What we need to do is find some way of storing the list in a smaller space without losing too much of the speed benefit. That basically means that we somehow need to map the ticket numbers into some more compressed range of values.
Starting to sound familiar? If you think back to an earlier video, I showed that we could use the modulus operator to derive constant length numbers from any other numbers.
This is where another little feature of hash functions that is commonly desired that I have not mentioned yet comes in handy. A lot of hash functions run at a very predictable speed, in fact in this case, given that our inputs (ticket numbers) are constant length, then in this case we can say that our hash function of choice will run in the same amount of time, no matter what the ticket number is.
The nuts and bolts
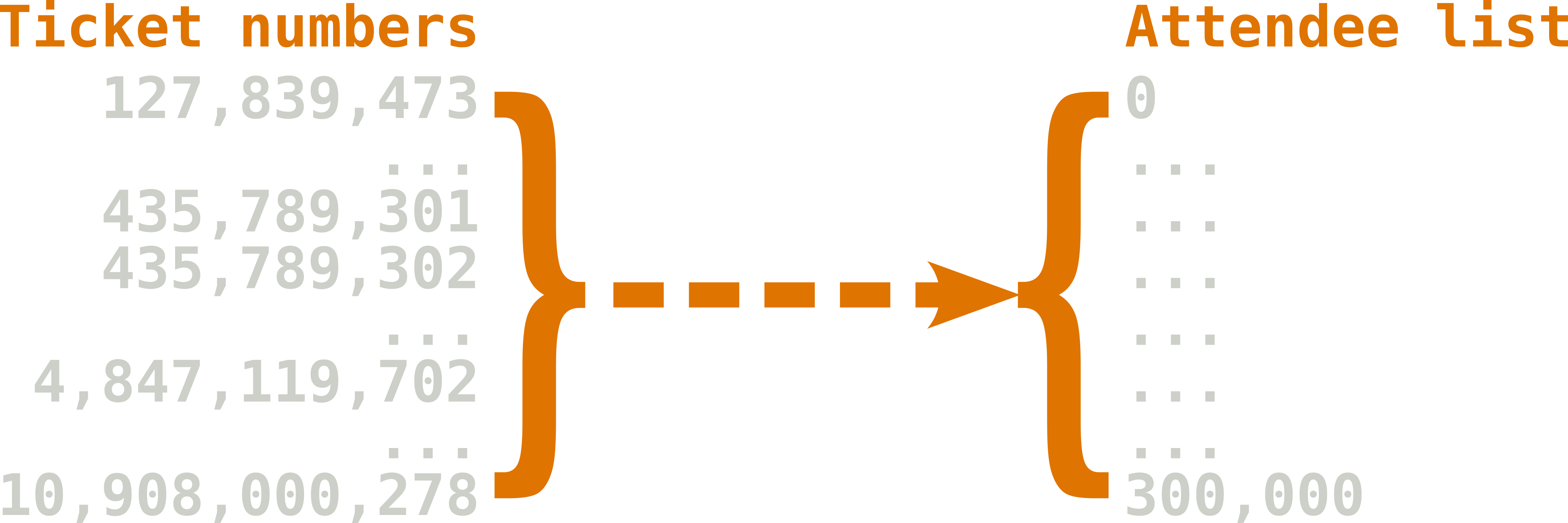
Let's get down to how this actually works. We know that we have 100 thousand attendees, so we know that we need a list least 100 thousand items long, but for reasons I will explain in minute, lets go with 300 thousand. Now, for our hash function, lets use the n mod m function from the previous article/video, and define our function as n mod 300000, this will ensure that the indexes we generate with this hash function are valid indexes for our list. At this point, what we have is a basic hash map. We can take ANY ticket number and generate an index to our list from it, and indicate at that index whether that ticket has been used to enter the concert, and we don't have to check every item in the list to check a ticket.
In practice, it is not quite this easy, nothing much ever is in the software world. The biggest complication is the reason that we want a list that is longer than the number of tickets we want to handle, and the cause is an issue with hash functions that I mentioned early on: collisions, that is, where two inputs to the hash function produce the same output. This means that we could have two tickets that end up indexing the same item in the list. There are many mitigations and solutions to this, but just to show a way it can be done, here is the simplest solution to this problem, called linear probing.
To deal with this situation we need to do two things. Firstly, we need to store the ticket number in the list at the index. This then allows us to check that the ticket number at the index matches the ticket number we used to generate the index. If the list item is empty, obviously we can just add the ticket number. If it matches, we know that that ticket has already been used and we can reject it. If it is not empty and it does not match is where the linear probing comes in. What we do in linear probing is to increment the index to the next index item. Once again, if it is empty, we add the value, if it matches, the item is already in the list, and we reject it, but if it is not empty and does not match, we increment the index again, and keep doing this until we either get a match, or we find and empty list item. The addition of the extra list entries over and above what is needed to hold all the ticket numbers is to reduce situations where this incrementing has to be done too many times, making it slow, so overall this larger list gets us very close to a constant time check on the ticket number without requiring an absurdly large list. If we assume that a individual check now takes longer, say 1 millisecond, which is 100 times longer than our original, that means that all the checks will now take about 100 seconds, which when compared to the original time of nearly 14 hours, I think makes the point.
So that just about sums it up for how we can design a simple hash set that uses hash functions to allow us to check things relatively efficiently. Thanks for reading, hope it was helpful.